前言
欢迎来到 RM-CV Wiki。
该仓库计划存放和 Robomaster 机甲大师对抗赛视觉/算法部分有关的内容。
该网页使用 mdBook 构建。
导航
友情链接
版权声明
除特别注明外,项目中除代码外的部分均在 CC BY-SA 4.0 协议之条款下提供。
基础知识
项目与构建
通常, 在最开始的编程学习中, 或者日常的使用过程中, 编写的程序通常由单文件组成. 这些程序通常不会用于解决复杂的问题, 且多数如流水式描述一个问题的处理过程 (也称 "脚本").
而随着待解决的问题逐渐变得复杂, 程序也将变得具有多种功能以应对各种需求. 这些程序通常会包含很多模块, 程序抑或调用这些模块完成工作, 抑或与这些模块相互协作配合, 完成任务.
程序调用的这些模块可能是自行编写而得, 亦有可能来自他人. 而纵观这些程序, 其中总会包含重复的部分. 而我们总是希望将这些重复的部分抽取出来, 一方面可以减少冗余, 另一方面可以方便维护.
我们通常将程序使用到的这些模块称为程序的 "依赖 (dependency)", 这种依赖关系可以是宏观上的经由用户界面的使用 (比如使用某个程序给出的命令行界面), 或者是编程语言层面的 API 调用. 后面一种形式被使用的依赖通常也被称作 "库 (library)".
何为项目
为了开发对于某个问题的解决方案, 我们通常会创建一个相应的项目. 一个项目往往会产出一个或多个可供最终使用的程序, 或者产出可被其他程序使用的 "依赖"; 当然, 项目也可能仅仅提供一些思路或者概念, 其概念是灵活的.
何为构建
维基百科上是这样定义 "构建 (build)" 1 的:
在软件开发领域, 构建 (build), 是指将源代码变成能够运行在计算机上的独立的 (standalone) 软件制品 (software artifact) 的过程; 也可以指上述过程的产物.
这样说起来可能比较抽象, 用具体的例子来说, 下面的场景就可以属于 "构建":
- 高级语言 (如 C++) 的源代码经过编译链接等操作后, 变成目标操作系统上可执行的二进制文件;
- 若干源文件经由 "静态网站生成器 (Static Site Generator, SSG)" 生成可以部署的静态网页2;
- ...
结合前面的内容, 生成项目目标产物的过程, 就是构建.
而构建的两个核心概念, 一个是要生成的 "目标", 另一个就是生成目标所需要的 "依赖".
构建工具
对于只有单个或者几个源文件的程序, 其构建过程往往不会很复杂, 通常只需若干命令就能完成.
而实际使用中, 就算只有几个文件, 其构建过程也不一定就能轻松管理.
以 C++ 多文件编程 (将在之后介绍) 为例, 单是完成一次单个目标的构建就需要键入多行命令来实现. 并且, 并不是每次生成可执行程序都需要编译所有的源文件: 只编译发生变动的文件, 可以节省相当一部分时间.
但是要由人工去核查每个文件是否发生变动却是很困难的事情. 且不说一个个核对文件的修改日期很容易出错, 源文件中还涉及到文件的相互包含 --- 如果一个文件发生了变化, 那么所有包含了该文件的源文件, 都需要被重新编译.
此外, 实际情况中, 一个包含多个程序构建目标的项目, 各个项目之间会涉及到很多文件, 有相同的也有不同的; 如若手动完成构建过程, 将会涉及到大量的记忆以及很多命令的键入.
总而言之, 这些过程对于常人来说是非常繁琐且容易出错的. 于是, 人们开发了构建工具: 只需要编写好构建工具能够读取的脚本, 描述整个项目该如何被构建 (比如哪些构建目标使用哪些文件), 构建工具就会自动完成构建过程, 生成所需的各个构建目标.
构建管理工具
然而构建工具的脚本编写也是容易出错的. 此外, 有些项目可能可以使用多种构建工具进行构建, 分别为这些工具编写脚本是费时费力的工作.
也有些项目需要对依赖进行管理, 比如依赖的获取, 甚至指定所使用依赖的版本等等.
相应的, 构建管理工具可以解决这些问题. 通过读取对应的配置文件, 构建管理可以完成依赖的获取安装, 构建脚本的生成, 构建等操作的自动化执行等等.
C++ 多文件编程
在上一节 "项目与构建" 中说到, 现实中的项目通常较为复杂, 由若干模块组成. 本篇文章将简单介绍一下 C++ 中的多文件编程.
多文件编程的好处
将代码分区放在不同的文件中,可以方便对于代码的查找、管理和协同工作.
此外,将代码分别放在不同的区块 (也叫做 "翻译单元 (translation unit)") 中, 可以实现在修改一些文件时, 不至于重新编译整个工程.
C++ 编译链接简介
先从最熟悉的单文件的情况说起. 下面是一个简单的 C++ 源文件,里面有一个 foo 函数和有一个 main 函数.
一个 C++ 程序需要有
main函数才能运行。
// demo.cpp
int foo(int, int); // foo 函数的声明
int main() {
// main 函数是一个程序的起点
int result = foo(3, 5);
return 0;
}
int foo(int a, int b) { // foo 函数的定义
return 2 * a + b;
}
可以看到, 上述的代码中,main 函数调用了 foo 函数. 但这不是件理所当然的事.
事实上, 在 编译 (compile) 过程中, 当编译器遇到 foo(3, 5) 这样的语句时, 会去查看是否存在这样的函数可供使用.
这个例子中, foo 函数的原型已在调用处之前声明, 因此编译器能够理解 foo(3, 5) 这样的语句.
int foo(int, int); // foo 函数的声明
具体来说, 对于该语句, 编译器会去查找,是否有一个名为 foo 的函数 声明 (declaration). 满足参数为两个 int 型整数的情况 (或者参数列表中参数类型支持从 int 类型转换而得); 如果没有, 编译器就会报错, 提示这个符号 "还没有在作用中被声明 (was not declared in scope)", 或者说这是一个 "未声明标识符 (undeclared identifier)".
但是现在还不能生成最终的可执行程序, 因为我们还不清楚 foo 函数的具体定义. 为此, 编译器会将这个符号加入到 未解决符号表 中。
在这个例子中, 编译器接着往下分析文件中的内容, 就会发现 foo 函数的定义, 并将其出现的位置记录下来, 供之后 链接 (Linking) 阶段的使用.
如此, 编译器就从源代码文件生成了目标文件. 在链接过程中, 编译器根据未解决符号表, 在每个编译得到的目标文件中查找对应的符号, 查找到之后, 就记录下相应的位置, 也就是将不同位置的代码 "链接" 起来.
在上面的例子中, foo(3, 5) 这个语句将会找到在 main 函数之后定义的 foo 函数, 因此被解决. 否则, 将会出现 "未解决的外部符号 (unresolved external symbol)" 或者 "未定义引用 (undefined reference)" 的错误.
也可以将函数和声明和函数定义写在一起, 比如下面这样:
// demo.cpp int foo(int, int) { return 2 * a + b; } int main() { int result = foo(3, 5); return 0; }
我们将每一个 C/C++ 源文件称作一个翻译单元 (translation unit)。那么在上述的例子中,我们的翻译单元会提供一个 int foo(int, int) 和一个 int main() 的符号,并且有一个 int foo(int, int) 的符号待解决。经过了链接过程,未解决符号得到了解决,于是就可以生成可执行程序了。
将文件拆开
假如 foo 函数是一个经常会被用到的函数, 那么在单文件的情况时, 往往每编写一个新的程序, 都需要将其复制到新的源代码文件中.
这样做会产生很多重复的内容, 不利于对代码的维护, 并且有可能增加额外的编译时间.
通过之前的内容, 不难想到, 可以将 foo 函数单独存放在一个文件中. 如此, 只要提供声明, 其他的代码可以成功调用该函数, 只要确保 foo 函数编译后所在的目标文件也参与链接过程即可.
接下来的例子中涉及到通过命令行操作编译器。读者只需要明白操作的目的即可,实际使用中不必要手动输入这些命令。
下面的 foo.cpp 是一个包含 foo 函数的源代码文件:
// foo.cpp
int foo(int a, int b) {
return 2 * a + b;
}
让编译器编译 foo.cpp 生成目标文件 foo.o:
$ c++ foo.cpp -c -o foo.o
不出意外的话, 当前目录下会多出一个名为 foo.o 的目标文件. 目标文件的内容一般不易为人类所阅读, 不过只要明白这个目标文件提供了 int foo(int, int) 这样一个符号即可.
而 main.cpp 将会写作下面的样子, 其中需要包含对 foo 函数的声明, 即可使用对应的函数, 并通过编译.
// main.cpp
int foo(int, int); // 只需要 foo 函数的声明
int main() {
int result = foo(3, 5);
return 0;
}
同样, 将 main.cpp 编译为目标文件:
$ c++ main.cpp -c -o main.o
类似的, 这个目标文件提供了 int main() 这样一个符号,但有一个 int foo(int, int) 的符号待解决.
最后, 为了生成最后的可执行程序 main, 我们需要将这些目标文件链接起来:
$ c++ main.o foo.o -o main
如果一切顺利, 将不会出现未解决符号, 可执行文件生成成功.
预处理指令
在编译之前, 编译器会先对代码文件进行预处理.
有很多预处理指令, 这些命令通常以 # 开始, 常见的有 #define、#include 等.
条件编译
一般来说, define 可以声明一个宏, 或者可以将代码中的宏名替换为相应的内容. 除此之外, define 也可以和 ifndef, ifndef 命令配合起来实现 "条件编译".
下面的代码中, 因为 define 过名为 FLAG 的宏 (macro), 因此 ifdef 命令条件为真, 故 #ifdef FLAG 和 #endif 之间的代码将会出现在预处理过的代码中; 反之, 如果没有定义过 FLAG, 其间的代码将不会出现在预处理之后的结果中.
#define FLAG
int foo(int, int);
int main() {
#ifdef FLAG
foo(3, 4);
#endif
return 0;
}
ifndef 的作用和 ifdef 相反. 即, 没有定义过相应的宏名, 才会满足条件. 下面的代码中, #ifndef FLAG 和 #endif 之间的代码不会出现在预处理的结果中.
#define FLAG
int foo(int, int);
int main() {
#ifndef FLAG
foo(3, 4);
#endif
return 0;
}
include 包含命令
include 命令则会将被包含文件的内容原样复制到文件的对应位置里. 这里不再举例.
使用头文件
在前面的例子中, 我们在 main.cpp 中手动写入了 int foo(int, int); 的声明. 但当声明较多时,手动编写或复制仍是比较麻烦的.
include 命令可以轻松实现代码的包含引入.
为 foo.cpp 编写相应的头文件 (header) foo.h 之后, 便只需在调用处 --- 比如 main.cpp 中 --- 包含 (include) 对应的头文件即可。
还是使用前文用到的例子, 接下来将其拆分成以下三个文件, 并添加一些其他的内容:
// foo.h
#ifndef FOO_H
#define FOO_H
int foo(int, int);
inline void func() { return; } // 内联函数
class A { // A 类型的声明
int num;
public:
A() = default;
int get_num() { // 直接写在类中的函数也是内联的
return this->num;
}
void set_num(int num_) {
this->num = num_;
}
void add(int m); // 成员函数的实现也可以放在 cpp 中(类外实现)
};
#endif // FOO_H
注意,foo.h 中使用 ifndef 等命令实现了该文件在每个翻译单元中仅会被包含一次。这叫做头文件保护 (header guards)。如果用户在一个源文件中不小心引用了两次头文件,或是包含的若干个头文件中都包含了某个头文件,那么将会出现同一个头文件在一个源文件中被引用多次的情况,即造成了重复声明。
此外,头文件中一般不能包含函数定义。试想,如果包含了函数定义的头文件被多个源代码文件包含,则这些源代码文件编译生成的目标文件中都会出现相同的符号。这会导致链接过程中链接器无法决定该使用哪一个符号。同理,也不应该使用 include 将函数定义的代码直接包含进源代码文件。
不过, 实际使用中也会出现需要将一些常用的函数放在头文件中的情况, 也就是说, 这一函数会在很多源文件中用到. 在经过编译后, 各个目标文件中均会出现这些相同的符号, 而我们不希望它们链接时发生冲突, 因此需要使用
inline关键字修饰它们.另一种情况是, 我们希望一个函数仅在当前翻译单元可用, 而在不同的翻译单元中可能存在同名但定义不同的函数. 这时应用
static关键字修饰它们.需要注意, 类的声明中直接写出的函数都会被视作
inline的来处理.
// foo.cpp
#include "foo.h"
static int f(int a, int b) { return a - b; }
int foo(int a, int b) {
a = f(a, b);
A inst_1; // 使用了 foo.h 中的 A 类型,因此需要引用 foo.h
inst_1.set_num(2 * a);
inst_1.add(b);
return inst_1.get_num();
}
void A::add(int n) {
this->num += n;
}
在 foo.cpp 中,同样引用了相对应的头文件,这是由于,头文件中可能包含了一些结构或类型的声明,或者包含其他的一些头文件。这时候,需要引用该头文件,否则编译时将会出现未声明符号的问题。
// main.cpp
#include "foo.h"
static int f(int a, int b) { return a + b; }
int main() {
int result = foo(2, 3);
int t = f(4, 5);
}
最后,main.cpp 中只需要调用 foo.h 中提供的符号即可。
在编译的时候,分别生成目标文件:
$ c++ foo.cpp -c -o foo.o
$ c++ main.cpp -c -o main.o
再执行链接操作:
$ c++ main.o foo.o -o main
参考资料:
- https://en.cppreference.com/w/c/language/storage_duration
- https://en.cppreference.com/w/cpp/language/storage_duration
代码库的概念
为什么要使用 "库"
在上一节中, 我们引入了 "多文件" 这样的方法, 来减少代码的重复, 提高代码的复用性.
而当我们把一类经常会被使用到的代码整理在一起, 就成了一个代码库.
而要理解库的概念, 建议从 "源代码" 和 "编译后" 两个层面进行.
提取代码成库
从源代码的层面来理解很直观, 就是把代码有条理的整理在一起.
接下来将通过一个例子, 来介绍之后的内容, 包括代码的提取整理成库, 以及之后的使用. 该示例所使用的代码也可以在 gitlab.com/kLiHz/cpp-multi-file-demo 查看.
假设我们现在有这样一个 C++ 文件 single_file_demo.cpp, 发现其中的 Date 相关代码有复用的价值, 因此计划将其拆分出来, 单独成库.
#include <iostream>
auto is_leap(int y) {
return (y % 4 ==0 && y % 100 != 0) || y % 400 == 0;
}
struct Date
{
int y;
int m;
int d;
Date(int y_, int m_, int d_) : y(y_), m(m_), d(d_) {}
};
auto calc_days(Date const & date) {
int days[] = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
if (is_leap(date.y)) {
days[2] = 29;
}
auto cnt = 0;
for (int i = 1; i < date.m; ++i) {
cnt += days[i];
}
cnt += date.d;
return cnt;
}
int main() {
int y, m, d;
std::cin >> y >> m >> d;
Date d1(y, m, d);
std::cout << calc_days(d1);
}
具体来说, 可以将代码中相关的 is_leap 和 calc_days 等函数, 变成 Date 类的成员方法. 结果如下:
// Date.hpp
// 头文件需要进行保护,目的是避免重复包含
#ifndef DATE_HPP
#define DATE_HPP
// 头文件中不能包含具体的定义
// 由于头文件可能会被多个 cpp (编译单元)包含
// 如果头文件中包含具体的定义,这些编译单元在最后链接过程中,会出现多个重复的符号
// 如果确需在头文件中包含具体函数的定义,需要声明为 inline(内联)
class Date {
int y;
int m;
int d;
bool is_leap(int year) {
return (year % 4 ==0 && year % 100 != 0) || year % 400 == 0;
}
public:
// 类的声明中直接书写的函数是 inline 的
Date(int y_, int m_, int d_) : y(y_), m(m_), d(d_) {}
// 也可以只写声明,再在 cpp 文件中实现这个函数
int get_days();
};
#endif // DATE_HPP
// Date.cpp
// 由于需要实现 Date.hpp 中声明的函数,需要包含 Date.hpp
#include "Date.hpp"
int Date::get_days()
{
int days[] = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
if (is_leap(this->y)) {
days[2] = 29;
}
auto cnt = 0;
for (int i = 1; i < this->m; ++i) {
cnt += days[i];
}
cnt += this->d;
return cnt;
}
如此, 我们便得到了一个库 (或者说是库的源代码/源代码形式的库), 该库由 Date.cpp 和 Date.hpp 组成. 使用该库的用户, 可以调用该库中的功能, 而不必重新编写代码.
库的分发形式
我们可以将这个库分享给其他用户使用, 一种方式便是以源代码的形式.
对于使用以源代码形式分发的库的用户来说, 一般会是像上一节中介绍的方式那样, 在需要使用库的地方, 引入头文件中的声明, 之后将自己的源文件和库的源文件均编译得到目标文件, 最后链接得到完整的可执行程序.
除此之外, 假如我们不希望公开库的源代码, 或者希望该库可以更方便地进行分发, 我们还可以将这个库构建为 (某个操作系统平台上的) 库文件. 构建成库文件的过程像是把多个目标文件 (假如库中包含多个源文件) 打包在一起, 但是不完全如此; 虽然目标文件中也是编译后的二进制代码, 但是它们更像是构建的中间产物, 而库文件可能会经过一些专门的优化, 更像是完善的商品.
相较于以源文件形式分发的库, 使用 (编译后的) 库文件不必花时间重新编译, 并且可以享受来自发布者的优化; 缺点则是, 使用过程中很可能遇到平台兼容性的问题.
详情可以参考 "ABI (应用程序二进制接口) 兼容性".
对于 C++ 来说, 有一种特殊的 "头文件库 (header-only libraries)". 顾名思义, 这种库只有头文件组成, 库中包含的代码都 (以源代码形式) 存储在头文件里, 因此用户只需在自己的程序中引用头文件即可使用库中的功能. 这种库的好处是携带使用起来都很方便, 缺点是会增加编译的时间.
此外, 对于以解释型语言 (比如 Python, JavaScript 等) 写成的库, 通常不存在编译这样的说法, 因为代码均需要解释器来执行, 所以分发时一般都是人类可以阅读 (但是不一定方便阅读) 的文本形式.
但是有几种情况涉及到 "编译" 或者类似的概念.
一是该库由一种更 "高级" 的语言写成, 需要编译器处理, 才能得到能够直接被解释器解释的代码;
二是为了便于传输, 代码会经过一种叫做 Minification (最小化) 的过程, 简单来说就是在不影响代码功能的情况下, 尽可能减少不必要的字符 (如空白, 换行等等), 缩短函数或变量的名字等等, 从而减小文件的大小, 便于传输.
类似的, 在 Obfuscation (混淆) 这一技术中, 也会涉及到函数和变量的重命名. 不过二者的目标不尽相同, 混淆的目的主要是为了增加用户破解软件的难度, 除了重命名之外, 可能还会增加一些无意义的干扰代码.
CMake 基本使用
构建工具
在 多文件的章节 中, 生成可执行文件 main 的过程, 也叫做 构建 (build) 可执行文件 main 的过程. 在这个过程中, 我们的 目标 是生成可执行程序 main.
简单来说, 生成这个目标需要 main.cpp, foo.h 以及 foo.cpp 三个文件.
更具体地说, 生成可执行程序
main依赖main.o和foo.o两个目标文件, 而这两个目标文件, 又分别由对应的cpp文件生成.

其中, main.cpp 和 foo.cpp 又依赖于 foo.h 文件 (因为包含了前二者包含了后者 foo.h).
假如目标文件对应的 cpp 文件发生了更改 (或者其所包含的头文件发生了更改), 都需要重新生成相应的目标文件, 才能保证最终链接之后生成的可执行程序是最新的.
不同于曾经的单文件, 现在要构建一个目标涉及到了多个文件. 有些问题需要解决:
- 每次都需要输入多条命令才能完成编译链接;
- 希望减少编译的时间, 只希望编译发生了更改的部分, 因此需要判断哪些文件发生了更改, 从而只对有必要重新编译的文件进行编译;
- ...
如果项目更多, 项目之间有依赖关系等等, 则可能需要输入更多更复杂的命令, 也需要留意更多的文件. 如果全由用户来做, 很容易出现差错.
构建工具可以帮助我们自动化上述的流程. 我们告诉构建工具生成目标需要哪些依赖, 构建工具就可以在每次我们需要重新构建目标时, 检测需要重新生成的文件, 并完成构建流程.
一些 IDE 会有自己的构建工具, 但对于初学者, 这个过程并不是那么明显. 往往, 用户将源代码添加进一个 "项目" 中, IDE 便将其视作生成该项目的依赖, 而不需用户显式指定.
使用外部库
以使用外部库为例, 这里使用上一节中整理出来的 Date 库作为例子.
那么该怎么调用这个外部库呢? 有多种情况, 一般来讲, 应当将该库的源代码与项目一同进行编译; 也有的时候, 库的开发者不提供源代码, 只有编译好的二进制文件和对应的头文件.
不管属于哪种情况, 都需要包含对应的头文件. 前者需要在链接时提供需要的目标文件, 后者则需要指定需要链接的库文件.
头文件包含
首先, 要想使用一个库, 头文件是不可少的. 它能够告诉我们能够使用符号, 并且能够帮助我们顺利完成翻译单元的编译, 从而生成目标文件.
在编译这些使用了外部库的项目时, 由于需要包含外部的头文件, 而外部头文件的位置则是千差万别, 因此一般需要给编译器指定头文件搜索的路径.
关于
#include命令的搜索范围: 当使用双引号""包含头文件时, 编译器首先查找当前工作目录或源代码目录, 然后再在标准位置查找. 而使用尖括号<>时, 编译器将在系统的头文件目录中查找.
比如, 下面的 demo.cpp 使用了 Date 库, 但是 #include 命令只是写出了 Date.hpp 的相对路径 (一般也建议这样做), 因此编译时需要指定头文件的搜索路径:
#include <iostream>
#include "Date.hpp"
int main() {
int y, m, d;
std::cin >> y >> m >> d;
Date d1(y, m, d);
std::cout << d1.get_days();
}
编译和链接
假设 Date.hpp 和 Date.cpp 都位于和 demo.cpp 同目录下的 Date 目录中:
下面的这些命令用于示范手动构建 (使用源码的外部库) 的过程, 读者不一定要亲自执行.
切换到 demo.cpp 所在目录下.
首先 编译 demo.cpp, 需要指定头文件搜索路径.
$ c++ demo.cpp -c -o demo.o -I ./Date # 编译 demo.cpp
执行这个命令后, 将在当前目录下得到 demo.o 这一目标文件.
接下来 编译 Date.cpp. 由于 Date.cpp 和 Date.hpp 处在同一目录下, 所以不需要指定头文件搜索路径.
$ c++ Date/Date.cpp -c -o ./Date.o # 编译 Date.cpp
执行这个命令后, 将在当前目录下得到 Date.o 这一目标文件.
最后, 将得到的两个目标文件链接起来, 生成最后的可执行文件.
$ c++ demo.o Date.o -o demo # 链接生成可执行程序 demo
需要注意的是, 上述命令的写法并没有体现库的使用, 只是手动的根据依赖情况分别编译源文件, 最后链接生成可执行文件.
现实世界中使用的很多外部库, 通常由包管理器进行管理. 库的头文件搜索路径, 以及要链接的库文件, 通常由包管理器负责记录. 通常有相应的程序, 可以根据这些记录来自动化生成编译命令, 而无需手动输入.
CMake
经过上述的例子, 可见手动完成构建是很复杂的. 当然, 可以使用构建工具 (如 GNU Make), 并编写对应的脚本, 但是由于其使用起来仍较为复杂, 不够抽象 (仍需编写具体的规则), 以下只介绍使用 CMake 的方法.
接下来的内容只概念性的介绍 CMake 的使用. 关于具体使用, 见下一节内容.
使用 CMake 这样一个构建管理工具, 只需编写一个 CMakeLists.txt 文件, 便可以生成用于不同构建工具的脚本.
最简单的 CMake 命令, 即是根据一个源文件, 生成一个可执行程序.
add_executable(single_file_demo "single_file_demo.cpp")
而对于本节中的示例项目, 编写 CMake 脚本也并不复杂.

首先, 为 Date 库编写一个 CMake 脚本. 下面的例子定义了一个名为 Date 的生成 "库 (library)" 的目标.
project(My-Date)
cmake_minimum_required(VERSION 3.13)
# 指定 C++ 版本
set(CMAKE_CXX_STANDARD 14)
# 创建一个库目标, 使用 Date.hpp, Date.cpp 两个源文件; 默认生成的是静态链接库
add_library(Date "Date.hpp" "Date.cpp")
# 设定库目标的包含路径
target_include_directories(Date PUBLIC .)
之后, 如果要使用这个库, 便只需要在 CMake 中使用 add_subdirectory 命令包含该目录 (作为子项目引入), 即可直接使用这个目标:
project(CPP-Multi-File-Demo)
# 提取库文件之前, 单文件的示例程序
add_executable(single_file_demo "single_file_demo.cpp")
# 子目录 Date 中的 CMakeLists.txt 中包含生成 Date 这个目标, 引入后便可以使用
add_subdirectory(Date)
# 创建一个名为 demo 的生成可执行文件的目标, 使用 demo.cpp 源文件
add_executable(demo "demo.cpp")
# 将 demo 和 "Date" 库进行链接
target_link_libraries(demo Date)
需要注意, 和上边手动操作时的示范不同, 这里 CMake 在构建时会真正生成一个库文件.
CMake 也会自动解析出项目之间的依赖. 比如:
- 编译
demo.cpp需要Date库的包含目录 (由target_include_directories命令得到); - 生成
demo需要demo.o和Date库, 即Date.lib(Windows) 或者libDate.a(Unix); - ...
如果 add_library 时使用 OBJECT 选项, CMake 将不会生成库文件, 而是将给出的源文件视作一个集合, 然后编译这些翻译单元为目标文件. 对于依赖它的目标, 则使用这些目标文件一并链接. 效果类似于逐一指明可执行程序目标需要的源文件, 但是使用 OBJECT 可以让 CMake 不去为每个可执行程序目标重复编译这些翻译单元.
add_library(Date OBJECT "Date.hpp" "Date.cpp")
自然, CMake 也可以生成动态库. 不过由于细节较多, 这里暂时不作展开.
开发环境配置和使用
Visual Studio Code 中 CMake 插件的基本使用
CMake 是一个构建管理工具。它可以根据用户编写的脚本生成适用于不同平台、不同工具链的构建文件。
安装 CMake
访问 CMake 官网 进入 CMake 下载页面,找到“Latest Release”,下载最新的发行版。
64 位 Windows 可以选择 Windows x64 Installer 下载即可。安装时,可以选择添加到 PATH 环境变量(Add to PATH)。
在 Visual Studio 中安装“C++ 桌面开发”的工作负载时,默认会安装 CMake。可以尝试从“Develop PowerShell for VS”中启动 Visual Studio Code。这样启动的 Code 中就会具有 Visual Studio 安装相关的环境变量。
在“‘开始’菜单”的“所有程序”下的“Visual Studio”目录中可以找到“Develop PowerShell for VS”的启动方式。
Visual Studio Code 中的使用
使用 Visual Studio Code 打开一个工作目录,这里以“CMakeDemo”为例。
在插件市场中搜索“CMake”关键字,安装 Microsoft 提供的“CMake Tools”插件(会自动安装另一个依赖的插件)。
在目录下新建这些文件:
CMakeLists.txt
project(CMake-Demo)
add_executable(demo "main.cpp" "foo.cpp" "foo.h")
add_executable命令用来告诉 CMake 添加一个“生成可执行程序”的目标。
foo.h
#ifndef FOO_H
#define FOO_H
int some_function(int a, int b);
#endif
foo.cpp
#include "foo.h"
int some_function(int a, int b) {
return 2 * a + 3 * b;
}
main.cpp
#include "foo.h"
#include <iostream>
int main() {
std::cout << some_function(1,2);
}
文件创建并编写完成后,可以按 Ctrl + Shift + P 打开命令面板,输入“configure”检索并执行“CMake: Configure”命令。也可以关闭窗口并重新打开,CMake 插件也会自动检测到当前文件夹下的这个 CMake 项目。
执行 Configure 操作时,CMake 插件会提示我们选择一个 Kit,根据需要选择自己需要使用的 Kit 即可。
如果没有问题,CMake 插件将会有类似如下的输出:
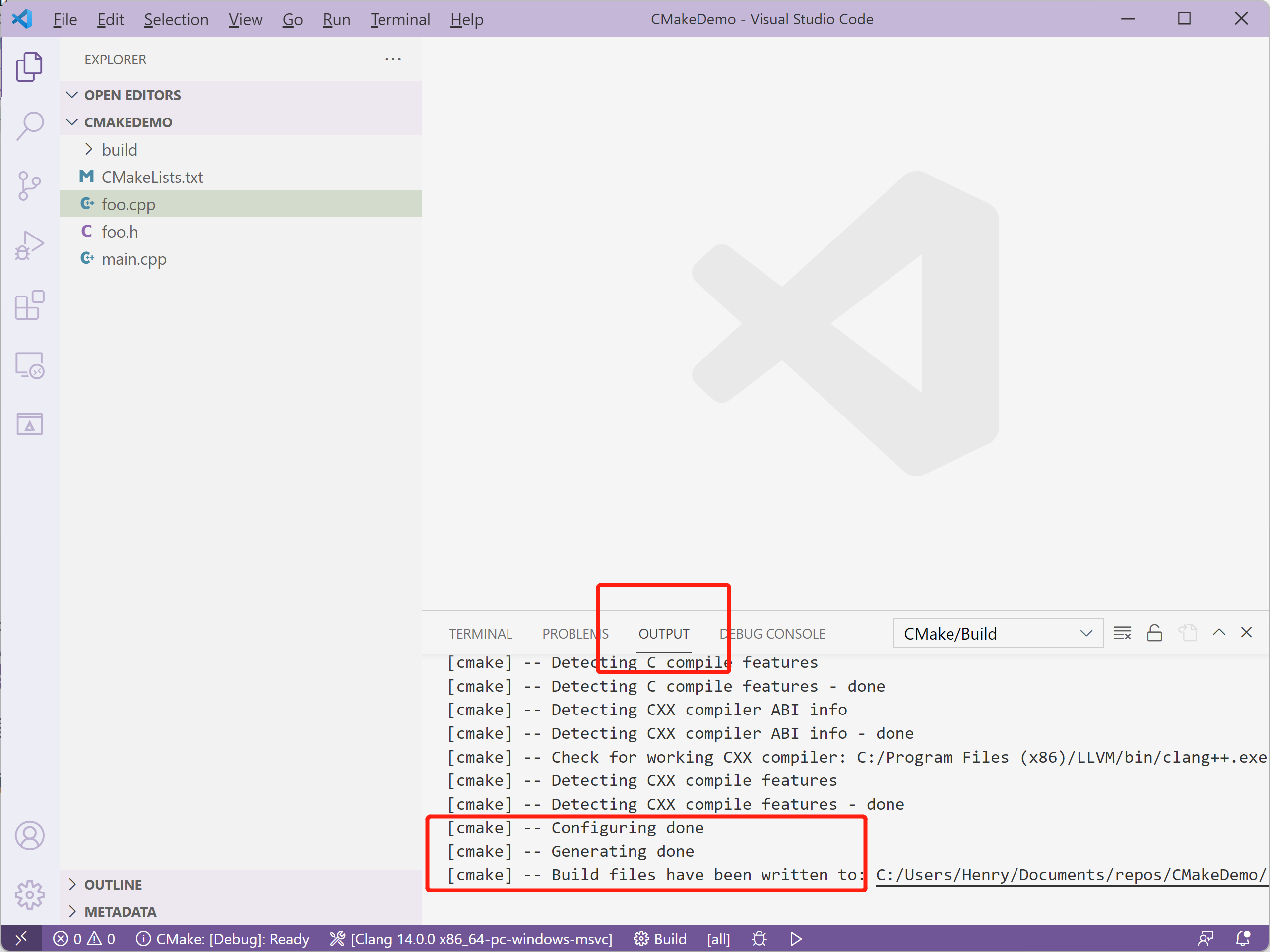
如果出现问题,可以尝试显式指定 CMake 使用的 Generator。
CMake 插件默认在 Visual Studio 窗口的底端提供了一些按钮:
⚙ Build 按钮旁的是要构建的目标,默认为 all,也就是所有的目标。
点击 ⚙ Build 按钮即可开始构建指定的项目。
CMake 插件默认的构建目录为工作目录下的 build 目录。CMake 生成的文件,以及构建产生的结果,都会在这个目录下。
这种方式称为“out-of-source build(在源代码之外构建)”,即构建相关的文件与源代码是分离开的,不会污染代码树。
🐞 和 ▶ 按钮分别为“调试运行”与“运行”;使用它们旁边的按钮可以选择要调试/运行的项目。
子项目
一个含有 CMakeLists.txt 文件的目录就可以视作一个项目。假如一个目录中下有多个 CMake 项目,也可以使用 add_subdirectory 命令将它们添加进来。
Windows 下使用 vcpkg + CMake 进行开发
vcpkg
vcpkg 是一款开源的、基于源代码的 C++ 依赖管理器。简单地说,用户可以使用 vcpkg 安装自己需要的 C++ 依赖。
将 vcpkg 的整个仓库克隆在本地,再执行提供的脚本,即可完成 vcpkg 的部署,详情参见 vcpkg 仓库的 README 或 网站上的说明材料。
无论是 vcpkg 还是之后安装软件包的代码,很多都是从 GitHub 取得的,因此可能需要用户具有相应的网络访问环境。
笔者实验时,vcpkg 会自动使用系统代理(如果进行了相应的配置),但执行
git clone需要在终端中手动设置 HTTP 和 HTTPS 代理服务器地址相关的环境变量。
vcpkg 的若干实例是互不影响的。可以在计算机上部署多个 vcpkg 的实例。
针对其这个特性,用户可以切换到 vcpkg 的目录下再执行命令,而不是将 vcpkg 可执行文件的路径添加到 PATH。
由于 vcpkg 是基于源代码的,因此在安装软件包之前,需要用户先安装微软的编译器 MSVC。除此之外,还需要额外安装 Visual Studio 的英语(English)语言包,才能顺利执行安装操作。
也可以使用 MSYS2 作为开发环境使用 vcpkg,但是笔者暂未实验,故不作展开。
以安装 OpenCV 为例
以安装 OpenCV 为例,用户在终端中切换到 vcpkg 的安装目录后,执行下面命令即可安装 OpenCV:
PS> ./vcpkg install opencv
需要注意,对于 OpenCV 以及其他一些包,vcpkg 在安装时有不同的 feature 可供选择。可以在 vcpkg 网站上检索包对应的信息,或者使用 ./vcpkg search <packagename> 进行检索。
比如,我们可以执行下面的命令,选择需要的 feature 并进行安装:
PS> ./vcpkg install opencv[core,dnn,jpeg,png,quirc,tiff,webp]
之后便会开始相对比较漫长的代码编译过程,可能会耗费约数十分钟或更久。同样,建议将 vcpkg 的目录添加进反病毒软件的排除项,可以加快速度。
除此之外,在 Windows 上,上述命令默认将会构建针对 x86-windows 平台的 OpenCV,我们还需要手动指定构建安装针对 x64-windows 平台的 OpenCV。
./vcpkg install opencv:x64-windows
编译过程中会产生很多文件(如 vcpkg 目录下的 buildtrees 目录,存放构建过程中产生的文件,如果保留可能会减少下次更新时花费的时间),可能会占用十数 GB 的磁盘空间。可以根据需要删除这些中间文件。
使用 vcpkg 中安装的包
在如上述文章安装好 OpenCV 后,只需要在 CMakeLists.txt 中使用 find_package(OpenCV REQUIRED) 即可引入需要的安装包。
在使用时可能还需要为 CMake 传入正确的参数,也就是 vcpkg 工具链的路径,具体操作将会在下文介绍。
CMakeLists.txt 示例
一个完整的 CMakeLists.txt 文件类似如下:
project(CMAKE_OPENCV_TEST)
cmake_minimum_required(VERSION 3.13)
find_package(OpenCV REQUIRED)
# message("${OpenCV_DIR}")
add_executable(main "hello.cpp")
target_link_libraries(main ${OpenCV_LIBS})
有些通过 vcpkg 安装的包,支持作为 CMake 目标引入,比如 {fmt} 库。
# 安装 fmt 库
PS> ./vcpkg install fmt
PS> ./vcpkg install fmt:x64-windows
这样的库安装好后,vcpkg 会有相应的提示:
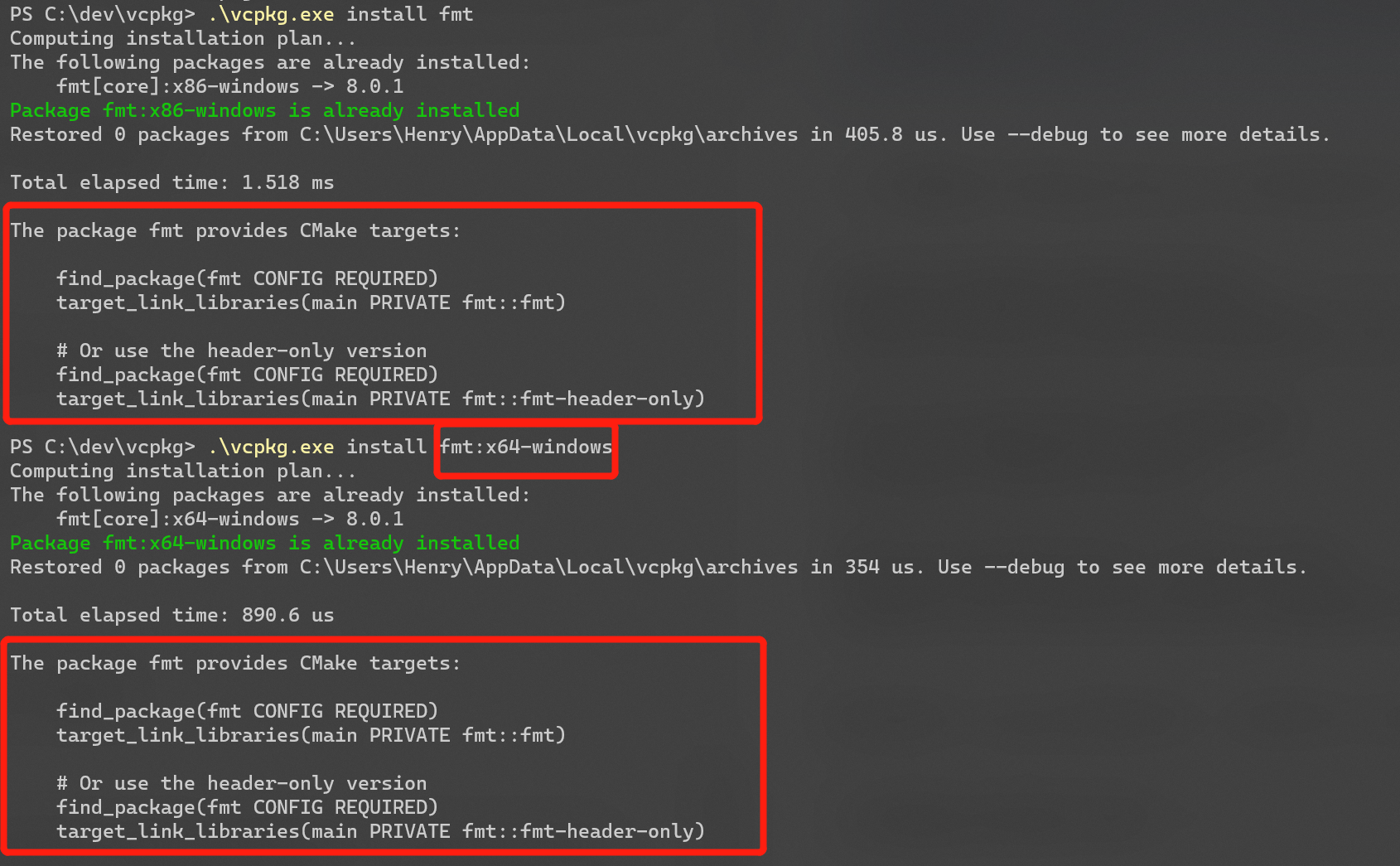 控制台最后输出如下:
控制台最后输出如下:
The package fmt provides CMake targets:
find_package(fmt CONFIG REQUIRED)
target_link_libraries(main PRIVATE fmt::fmt)
# Or use the header-only version
find_package(fmt CONFIG REQUIRED)
target_link_libraries(main PRIVATE fmt::fmt-header-only)
也就是说,在 CMakeLists.txt 中可以这样子使用这样的库:
project(CMAKE_VCPKG_FMT_TEST)
cmake_minimum_required(VERSION 3.13)
find_package(fmt CONFIG REQUIRED)
add_executable(main "hello.cpp")
target_link_libraries(main fmt::fmt)
# 或者使用“仅头文件(header-only)”版本的 fmt
# target_link_libraries(main fmt::fmt-header-only)
CMake 传参
在 CMake 配置过程中,需要将 vcpkg 目录下的 scripts/buildsystems/vcpkg.cmake 文件路径,作为 CMAKE_TOOLCHAIN_FILE 变量传入,这样 CMake 就可以识别到该 vcpkg 实例中安装的包了。
比如,假设 vcpkg 的目录位于 C:/dev/vcpkg/,则需要在 CMake 的“Configure Args”中添加:
-DCMAKE_TOOLCHAIN_FILE=C:/dev/vcpkg/scripts/buildsystems/vcpkg.cmake
这个选项通常可以在 IDE 的构建选项中找到。如果使用命令行界面,则可以采用类似如下的命令:
cmake \
-B [build directory] \
-S . \
-DCMAKE_TOOLCHAIN_FILE="[path to vcpkg]/scripts/buildsystems/vcpkg.cmake"
需要注意,如果路径中包含空格,在 Shell 需要使用引号将路径包裹起来,以便Shell 将其视作一个整体传递给 CMake 程序。但如果在 IDE 中,则需要根据具体情况判断是否需要使用引号将路径包裹起来(即,IDE 在传递参数时,是直接将字符串传入给可执行程序,还是将其拼接在命令的最后并通过 Shell 界面执行命令)。
如果有其他需要转义的字符,也需要根据 IDE 配置参数的方式,决定是否需要转义。比如,如果 IDE 使用配置文件的形式进行配置,则可能需要按照字符串字面量的转义方式对特殊符号进行处理;假如是在图形界面中输入的,则一般不需要对特殊符号进行转义。
Visual Studio Code + CMake Tools
VS Code 中的配置实际上是修改 CMake Tools 插件的配置,关于插件的使用见上一篇博文。
在 VS Code 的设置中搜索 "CMake: Configure args" 选项,点击 Add Item 添加上一节中提到的参数。
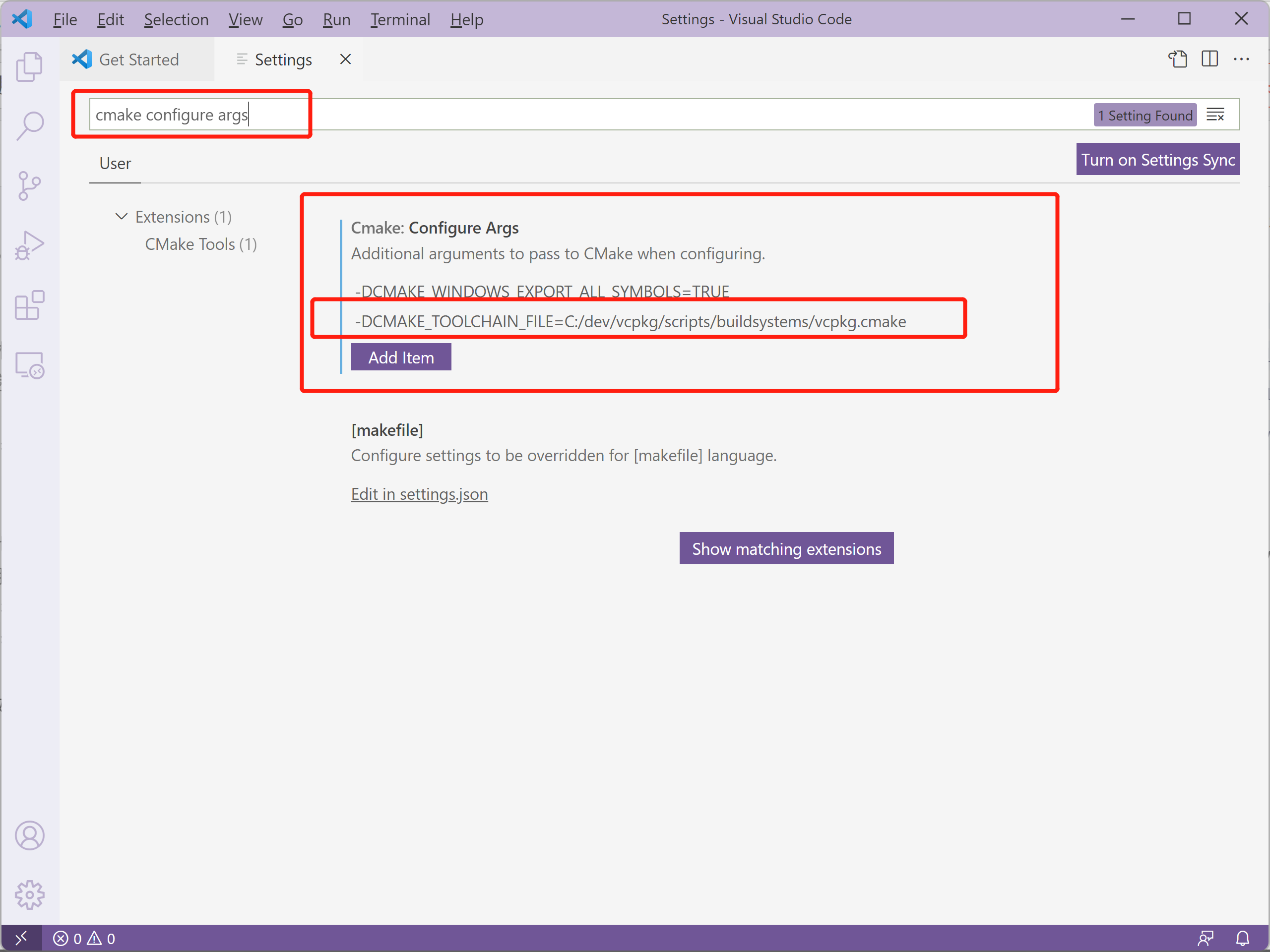
这个选项也可以设置成目录的 (而非全局的), 也就是在工作目录下新建一个 .vscode 目录, 在其中新建一个 settings.json, 并确保其中有一个键名为 cmake.configureArgs 的列表, 其中包含相应的要传递给 CMake 的选项.
向列表中添加一个定义 CMAKE_TOOLCHAIN_FILE 变量的选项, 而最后的 .vscode/settings.json 文件类似如下:
{
"cmake.configureArgs": [
"-DCMAKE_WINDOWS_EXPORT_ALL_SYMBOLS=TRUE",
"-DCMAKE_TOOLCHAIN_FILE=C:/dev/vcpkg/scripts/buildsystems/vcpkg.cmake"
]
}
Visual Studio
确保在 Visual Studio 中打开的是一个 CMake 项目.
在 "项目" 菜单里选择 "<项目名> 的 CMake 设置", 之后找到 "命令参数", 并在其中添加要使用的选项.

这会在 CMake 项目下生成一个 CMakeSettings.json 文件. 在上述图形界面里的修改都会同步存储到这个文件里.
我们可以在某个配置 (比如 x64-Debug) 下的 cmakeCommandArgs 里添加相应的参数:
{
"configurations": [
{
"name": "x64-Debug",
"generator": "Ninja",
"configurationType": "Debug",
"inheritEnvironments": [ "msvc_x64_x64" ],
"buildRoot": "${projectDir}\\out\\build\\${name}",
"installRoot": "${projectDir}\\out\\install\\${name}",
"cmakeCommandArgs": "", // 在这里添加相应的参数
"buildCommandArgs": "",
"ctestCommandArgs": ""
}
]
}
CLion
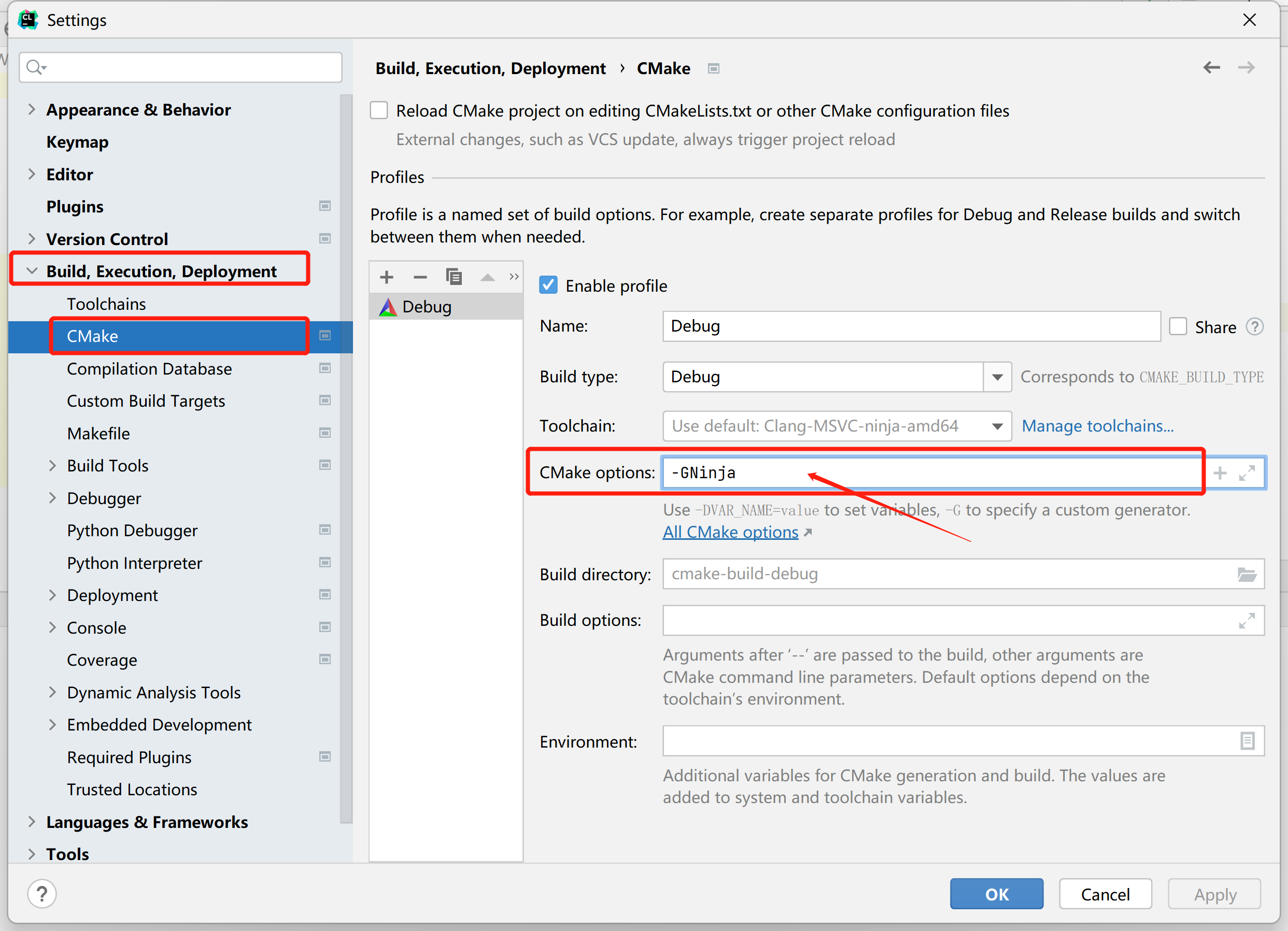
CLion 的配置也是类似,在 "文件 (Files)" → "设置 (Settings)" → "构建, 执行, 部署 (Build, Execution, Deplyment)" → "CMake" 中, 在某个配置中的 CMake options 中添加要传递给 CMake 的选项.
使用 SSH 连接到 GitHub
用户可以使用 SSH 协议连接到服务器, 以及进行到远程服务器的认证过程 (认证远程服务器的身份, 以及向服务器证实自己的身份).
当然, 用户可以用 SSH 来读写自己在 GitHub 上的存储仓库中的数据 (并且也推荐这样做). 使用 SSH 建立连接的时候, 用户使用自己本地电脑上一个私有的密钥文件来完成认证.
简单来说, 要配置 SSH 连接, 需要以下两步:
- 生成一个 SSH 密钥文件
- 将 SSH 密钥添加到自己的 GitHub 账号中
之后就是通过 SSH 访问仓库了 (拉取或推送更新). 但是请别着急, 这中间有一些需要注意的地方.
关于 SSH
SSH, 全称为 "Secure Shell Protocol", 是一种加密的网络传输协议, 可在不安全的网络中为网络服务提供安全的传输环境. 最常见的用途是用来远程登录系统, 远程执行程序, 传输命令行界面等.
SSH 以 非对称加密 实现身份验证. 身份验证其实有多种途径, 常见的一种就是使用密码进行验证的方式, 这个过程中一般是使用自动生成的公钥和私钥来简单地加密网络通信, 以便安全地传输密码; 另外一种就是手动生成一对公钥和私钥, 并使用这些密钥进行认证, 这样便不再需要密码了.
其中, 公钥需要传输给待访问的计算机中, 而相应的私钥则应由用户自行保管.
这里需要介绍一下非对称加密的大概过程.
- 用户在和远程计算机通信前, 需要拥有远程计算机的公钥, 远程计算机也应拥有用户的公钥;
- 在用户向远程计算机发送报文时, 用户先使用对方的公钥对报文进行加密, 得到密文后, 对方可以使用自己的私钥进行解密 (由于私钥是妥善保管的, 因此理论上只有远程计算机能够解密报文);
- 同时, 用户使用自己的私钥对报文进行签名, 该签名可以使用该用户的公钥进行验证 (任何拥有公钥的人都可以验证身份, 但是不能伪造身份).
如果过程反过来, 即远程计算机要向用户发送报文的时候, 也是一样的过程.
因为 SSH 只验证用户是否拥有与公钥相匹配的私钥, 相信读者在阅读了上面的内容后一定能够明白, 在使用 SSH 时, 核实未知密钥的来源 是非常重要的事情, 也就是说, 如果接受了攻击者的公钥, 就相当于是将攻击者视为合法用户了.
比如, GitHub 就在自己的文档网站上, 给出了 自己 SSH 密钥的指纹.
密钥指纹可以供用户验证自己到远程服务器的连接. 在用户首次通过 SSH 访问 github.com 时, 程序会提示是否将主机添加到信任列表, 这个时候就会显示远程主机的密钥指纹. 这个时候用户需要比对程序中显示的密钥指纹和网站上公布的是否有差误. 如果有问题, 则不应信任该连接 (或者说该公钥).
当然, 用户也需要将自己的公钥提供给 GitHub (github.com), GitHub 才会允许连接.
那读者可能会问, 那上述提及的查看密钥指纹以及提供密钥的过程是怎么做到安全可信的呢? 这些过程都是经过网页来进行的, 而我们日常使用 HTTPS 的网页浏览中已经使用了非对称加密; 不过具体的原理和详情这里不再阐述了, 读者可以自行搜索相关资料.

生成 SSH 密钥
说了这么多, 那么究竟该如何操作呢?
查看已有的 SSH 密钥
如何查看自己计算机上是否已经有 SSH 密钥了呢? 可以查看 ~/.ssh 目录下的文件 (对于 Windows 来说, 一般为 C:/Users/<username>/.ssh, 类 Unix 系统则为 /home/<username>/.ssh), 看是否有类似如下文件名的文件:
- id_rsa.pub
- id_ecdsa.pub
- id_ed25519.pub
其中, .pub 后缀表示该文件是公钥文件, 同时应该会有一个与之同名但名没有后缀的文件, 即为私钥文件.
如果不存在这样的文件, 或者根本不存在 .ssh 目录, 则说明计算机上不存在 SSH 密钥的文件.
创建 SSH 密钥
Windows 上的 Git for Windows 已经包含了 OpenSSH. 其他操作系统则可能需要手动安装 openssh 软件包.
下边以 Windows 上使用 Git for Windows 为例, 介绍创建密钥的过程. 其他操作系统应当与 Git Bash 的操作过程类似.
使用 ssh-keygen 命令创建密钥 (注意替换为自己在 GitHub 上的电子邮件地址). 这里选用的是 ED25519 算法; 若选用其它的算法, 则命令和生成的文件名会有不同.
$ ssh-keygen -t ed25519 -C "your_email@example.com"
之后会提示选择密钥存储的路径; 为了方便, 建议 使用默认的路径, 直接按回车即可:
> Enter a file in which to save the key (/c/Users/you/.ssh/id_rsa): [按 Enter 键]
之后还会提示设置 "通行口令", 也就是打开 (使用) 密钥时需要的密码. 之前已经说过, 私钥应当妥善保管, 任何时候都不应该泄露给他人. 这里使用口令的目的是添加另一层保护, 不过也可以留空, 直接按回车即可.
如果设置了口令, 则在每次使用密钥的时候都需要输入口令. 也可以使用 ssh-agent, 将其配置为缓存通行口令. 笔者觉得这样较为繁琐, 便没有配置 ssh-agent, 接下来的文章也不会介绍, 读者如有需要可以自行参考相关资料.
> Enter passphrase (empty for no passphrase): [输入一个口令]
> Enter same passphrase again: [再次输入口令]
如此便会在 ~/.ssh 目录下生成身份验证所需的公钥和私钥两个文件. 上文中使用的 RSA 算法, 所以得到的文件默认应为 id_rsa (私钥) 和 id_rsa.pub (公钥).
添加 SSH 密钥
登录 GitHub 后:
- 在页面的右上角找到个人资料图像, 点击后会出现菜单, 选择 "Settings";
- 之后在侧边栏的 "Access" 分区下, 找到 "SSH and GPG Keys", 点击进入页面;
- 在 "SSH Keys" 标题下找到 "New SSH Key", 点击进入页面;
- 在 "Title" 对应的文本框内填写该密钥的名称, 用于区分; 比如如果当前待添加密钥是自己的 Windows 笔记本上的, 则可以用 "Windows Laptop" 作为标题;
- 之后将公钥文件中的内容复制进入 "Key" 对应的文本框中;
- 最后点击 "Add SSH key" 完成添加, 注意这时可能会要求用户再次输入 GitHub 账户密码以确认身份.
其他平台的配置过程应当类似.
测试 SSH 连接
使用下面的命令测试到 GitHub 的连接:
$ ssh -T git@github.com
如果初次连接到 github.com, 会有类似如下的警告:
> The authenticity of host 'github.com (IP ADDRESS)' can't be established.
> RSA key fingerprint is SHA256:nThbg6kXUpJWGl7E1IGOCspRomTxdCARLviKw6E5SY8.
> Are you sure you want to continue connecting (yes/no)?
这时我们需要 验证消息中的指纹 (fingerprint) 是否与 GitHub 的公钥指纹 一致. 如果一致, 则输入 yes 并按 Enter 提交, 之后本地计算机将会记录该公钥, 将其加入 github.com 的已知主机中.
之后, 验证返回的消息中是否包含了自己的用户名.
至此, 添加完成, 可以使用 SSH 访问 GitHub 上的仓库了. 如果本地已有仓库, 使用的是 HTTPS 链接作为远程 URL, 可以修改为 SSH 链接. (目前 GitHub 已强制要求使用 SSH 连接完成向远端仓库的推送.)
查看当前仓库的远程 URL:
$ git remote -v
修改 URL (以修改 origin 为例):
$ git remote set-url origin git@github.com:USERNAME/REPOSITORY.git
修改完成后可以使用上述命令验证是否修改成功.
其他注意事项
正如上文所说, SSH 比较安全, 并且就目前来说, 大陆对 GitHub 的 HTTPS 访问已经被阻断, 但是 SSH 尚能正常使用. 当然这并不意味着通过 SSH 访问, 就是安全而不会被发现的.
参考链接
编程技巧
C++ 浮点数转为字符串
C++ 如何将浮点数转为字符串,并保留一定小数位数呢?比如有一个数 25.56789,只想保留小数点后两位。
sprintf、snprintf 是比较 C 语言的函数,用法也比较简单,本文不再过多介绍,接下来主要介绍一些 C++ 的写法。
先放参考链接:
1. std::stringstream
直接上代码:
#include <sstream>
auto formatDobleValue(double val, int fixed) {
std::ostringstream oss;
oss << std::setprecision(fixed) << val;
return oss.str();
}
2. std::to_string + 求子串
虽然 std::to_string 不支持指定格式化小数的位数,但是我们可以用求子串的方式得到我们想要的结果。
#include <string>
auto formatDobleValue(double val, int fixed) {
auto str = std::to_string(val);
return str.substr(0, str.find(".") + fixed + 1);
}
3. std::to_chars (C++ 17)
std::to_chars - cppreference.com
Bartek's coding blog: How to Convert Numbers into Text with std::to_char in C++17 (bfilipek.com)
#include <charconv>
#include <system_error>
#include <string>
#include <array>
auto formatDobleValue(double val, int fixed) {
std::array<char, 10> str; // char str[10];
auto [ptr, ec] = std::to_chars(str.data(), str.data() + str.size(), val,
std::chars_format::fixed, fixed);
if (ec == std::errc()) {
return std::string(str.data(), ptr - str.data());
}
else return std::string();
}
#include <iostream>
int main() {
std::cout << formatDobleValue(0.12345, 3) << "\n";
}
但是很遗憾,截至目前,貌似只有 MSVC 支持除整型以外的重载。估计大家觉得,既然有了 std::format,std::to_chars 就显得比较鸡肋了……
c++ - What is the correct way to call std::to_chars? - Stack Overflow
4. std::format (C++ 20)
此外,还可以采用 C++ 20 的 std::format!
#include <iostream>
#include <format>
int main() {
std::cout << "Hello World!" << std::endl;
std::cout << std::format("{:.3f}", 22.1234345) << std::endl;
}
是不是简单很多?最新的 Visual Studio Preview 已经支持了,快去试试吧!
需要指定 C++ 版本为 20。建议用 CMake 指定项目的 C++ 版本,方便多了。
cmake_minimum_required(VERSION 3.1)
project ("CProgramming")
set(CMAKE_CXX_STANDARD 20)
add_executable(hello hello.cpp)
TX2 使用笔记
初识 TX2——暨嵌入式开发之旅启程
TX2 即 NVIDIA Jetson TX2 的简称。
最开始不理解 TX2 的构造,完全就是个很高级的存在,而且看起来也和网上搜到的图片不一样——网上的图片很大一个,我们手上的确很小,甚至一直怀疑我们的是否是 TX2,后来一点点才理解到这个东西。
其实当时多上淘宝查一下应该也能明白。
这里就不卖关子了,现在就来介绍一下这 TX2 的构造,首先是有一个 TX2 核心板,然后有一个载板(carrier board),载板上有各种接口,同时负责供电。核心板需要载板才能工作。
之前让我疑惑的地方就在载板上,这载板有很多种,NVIDIA 官方的就很大,然后又有很多厂家也会设计第三方的载板,它们往往更小,在功能、性能上往往也有变化,甚至自己都可以设计一个。但是第三方的就会存在兼容问题,在给 TX2 安装系统时,需要额外刷入固件包,也会麻烦一些。
官方的板子就不说了,一切都比较简单,网上直接搜 TX2 也有不胜其数的上电记录。
下边有几点疑问:
- 为什么叫上电而不是开机呢?为什么也有人要管TX2叫开发板呢?
- 嵌入式系统和平时家用的桌面 PC 有什么不一样呢?
- 板级支持包(BSP,Board Support Package)是什么?
- 设备树(Device Tree)又是什么呢?
在 TX2 上使用代理
在 TX2 上使用代理和在其他 Linux 系统上是类似的。
也许读者在其他平台有过使用代理的经历,那样也请暂时放下已有的经验,参考一下本教程的方法。
订阅和订阅链接
一般的,在用户购买服务后,网络代理服务商需要将代理服务器的连接信息提供给用户,一般为某种代理软件所支持的配置文件格式,且通常会提供适用于多种软件的配置文件。
此外,这些信息一般是以“订阅”的形式提供的。我们通过“订阅链接”,可以随时获取到最新的代理服务器信息。
需要注意,一定要保护好自己的订阅链接,不得在公共网络上明文传输。
TX2 本机上运行代理软件
读者可能已经使用过类似 Clash for Windows 这样的图形化软件. Clash 本身是一款 CLI 程序 (命令行界面程序), 不过有很多应用程序基于其设计了易于使用的图形界面程序.
但是出于各种原因, 笔者并不推荐使用 Clash 及其衍生的各种软件.
因此将原文内容删除, 并将于之后更新另外的方法.